

Você já conhece os tão falados containers ? E o Docker ? Sabe a diferença entre containers e máquinas virtuais ? Neste artigo, vamos abordar os fundamentos da Conteinerização, uma tecnologia não tão recente, mas que está sendo bastante popularizada pelo Docker.
Particularmente, acho a ideia por trás dos containers genial e realmente acredito que esse é um caminho sem volta: em breve, todos profissionais de operações e desenvolvimento precisarão dominar esta tecnologia.
Virtualização
Na primeira postagem desta série de ferramentas de apoio a times DevOps, vimos que a virtualização é uma tecnologia bastante disseminada no mundo da TI: em um sistema hospedeiro (host), temos a possibilidade de executar diversos sistemas operacionais convidados (guests) através do Hypervisor, que abstrai os recursos do host e fornece-os aos guests.
Relembre a figura a seguir:
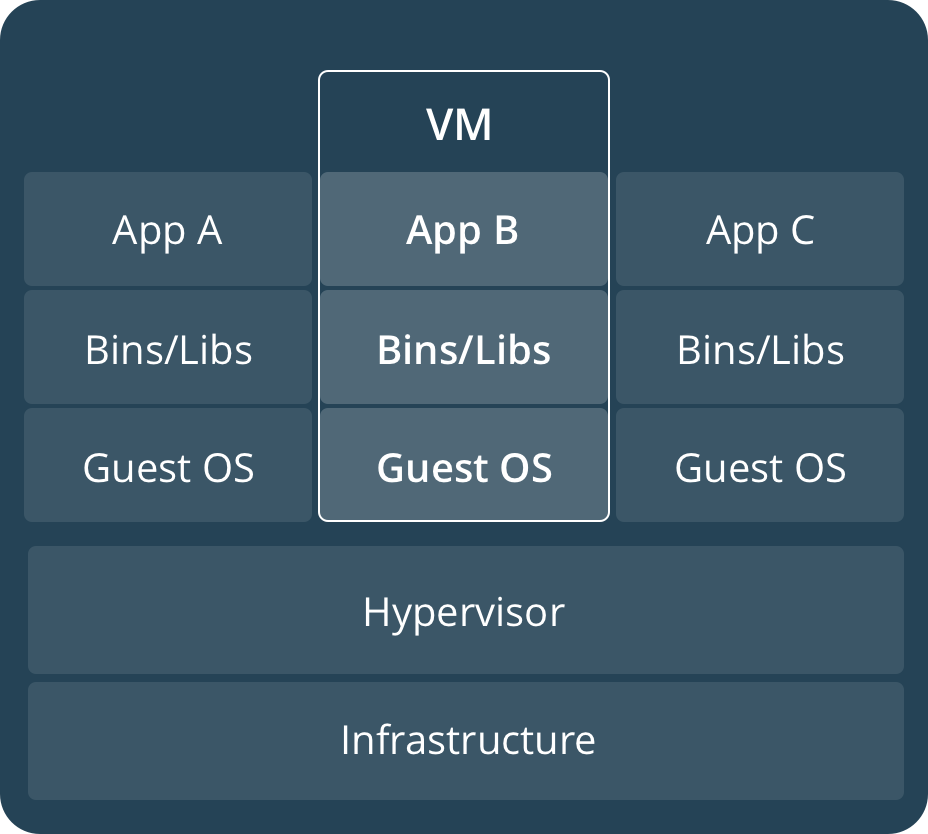
Fonte: Docker.com – Máquina Virtual tradicional
Observe que na camada mais baixa temos a infraestrutura do hospedeiro. Logo acima do hospedeiro, vem o hypervisor e então as diversas máquinas virtuais (com seus sistemas operacionais completos, bibliotecas, aplicações, etc). Na figura acima, o Sistema Operacional de cada máquina virtual (Guest OS) é executado por completo: se tivermos 10 máquinas virtuais com Debian, teremos 10 Kernels em execução e 10 conjuntos de aplicativos e bibliotecas que compõem o Debian, consumindo memória, disco e recursos. Além disso, temos o hypervisor, que é o componente da solução de virtualização que abstrai o acesso à Infraestrutura/hardware do hospedeiro.
Entre as ferramentas de virtualização mais famosas, podemos citar o VMware, VirtualBox, Xen e o QEMU. Também já vimos nos artigos anteriores o Vagrant, que facilita o gerenciamento de máquinas virtuais em ambientes de desenvolvimento (Vagrant: Turbine suas VMs e ambientes de desenvolvimento – DevOps Parte 1 e Vagrant: Crie sua própria box e disponibilize-a na Vagrant Cloud – DevOps Parte 2).
Conteinerização
Mas como funciona a conteinerização ? Dê uma olhada na figura a seguir:
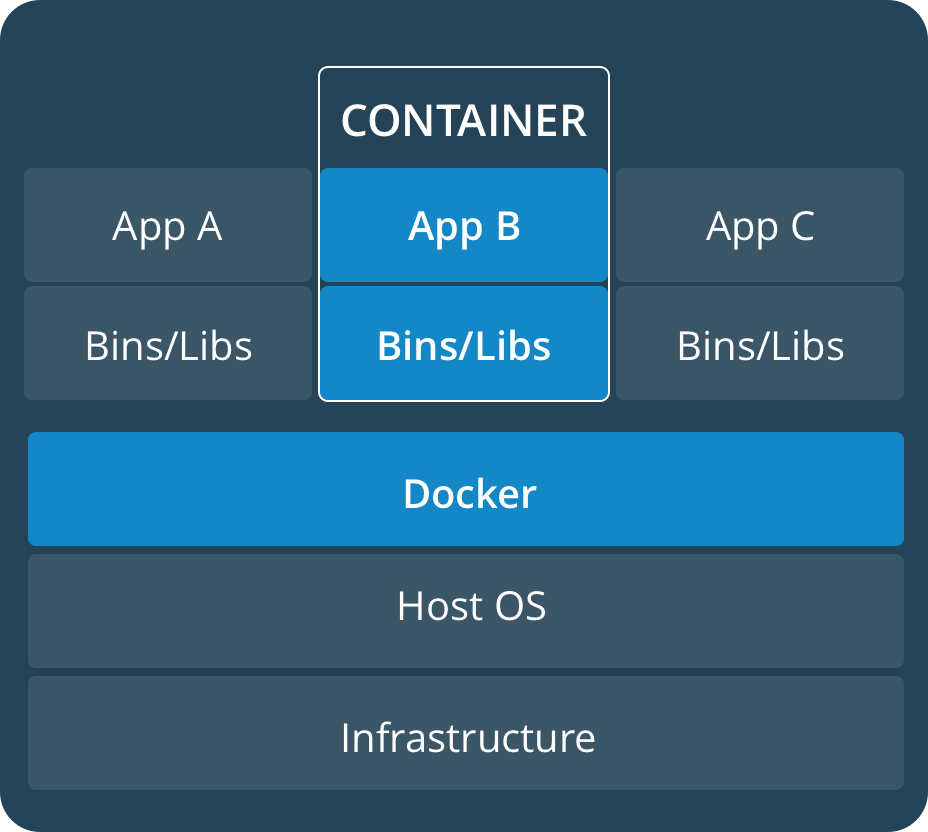
Fonte: Docker.com – Containers
Observe que apenas o sistema operacional do hospedeiro (Host OS) está em execução, ou seja, não temos mais a figura do Guest OS nem a do hypervisor. Isso indica que apenas o Kernel do hospedeiro é executado e o Docker fornece acesso ao Kernel do hospedeiro para os containers, mas mantendo um nível de isolamento entre eles.
Dá uma olhada no que o Docker Overview fala:
Containers are lightweight because they don’t need the extra load of a hypervisor, but run directly within the host machine’s kernel. This means you can run more containers on a given hardware combination than if you were using virtual machines. You can even run Docker containers within host machines that are actually virtual machines!
Assim, por não demandar um Kernel próprio sendo executado, os containers ficam bem mais leves que as máquinas virtuais, possibilitando uma melhor utilização do processamento e recursos disponíveis. Também não temos a figura do Hypervisor, que adiciona uma carga de processamento e emulação nas soluções de virtualização.
LXC – LinuX Containers
O Docker nasceu em 2013 e foi construído com base em um projeto chamado LXC (LinuX Containers), que foi criado em 2008 (por isso falei que a tecnologia de conteinerização não é tão recente).
No lançamento, o LXC foi chamado de Chroot com esteróides. Se você não conhece, o Chroot permite mudar o diretório raiz de um processo e de seus filhos no Linux, impedindo-os de acessar arquivos fora daquele diretório. Dizemos que os processos estão “aprisionados”, o que traz um certo nível de isolamento entre o processo e o sistema operacional.
O LXC utiliza várias funcionalidades no Kernel do Linux, como namespaces, Apparmor, SELinux e Chroot, possibilitando a criação de containers com um grau de isolamento bem mais satisfatório que o próprio Chroot. Se quiser conhecer um pouco mais sobre Chroot e LXC, inclusive com exemplos de como o isolamento do LXC é superior ao do Chroot, dê uma lida no excelente artigo Adeus chroot… seja bem vindo LXC… do Blog Vinipsmaker.
Tá, sabendo de tudo isso, qual o problema com o LXC e porque o Docker ? Um dos principais motivos é que a usabilidade do Docker é bem melhor que a do LXC. O Docker criou várias abstrações que facilitam a criação e gerenciamento dos containers, abstraindo detalhes de mais baixo nível e facilitando o uso por profissionais de operações e desenvolvimento.
Alguns dos benefícios adicionais do Docker frente ao LXC listados nas Perguntas Frequentes do Docker:
- Deploy portável: se você cria uma aplicação em LXC e envia para deploy em um uma máquina diferente, dificilmente você conseguirá executá-la sem configurações adicionais para a nova máquina. Já o Docker criou um formato para empacotar as aplicações e suas configurações em containers portáveis, sendo possível executá-los em máquinas diferentes, com configurações diferentes (inclusive com sistema operacional e Kernel diferentes);
- Build automático: o Docker inclui uma ferramenta para construir um container a partir de código fonte (o código é mantido em um arquivo chamado Dockerfile);
- Versionamento: é possível criar versões de containers através de imagens hospedá-las em um servidor, chamado de Docker Registry.
Docker
No Docker, temos dois conceitos fundamentais:
- Containers, que são executados pelo Docker Daemon (Docker Server) e são criados a partir de uma imagem;
- Imagens, que contém o conjunto de aplicativos e bibliotecas (Bins/Libs) que serão disponibilizados para o container, como Java, Apache, Ngnix, Rails, etc. O conceito aqui é bem similar às boxes que vimos no Vagrant.
Um grande benefício do Docker é a utilização dos Union File Systems (UnionFS), que são sistemas de arquivos que possibilitam a criação e reutilização de layers (camadas) nas imagens que servem de base para os containers, poupando espaço em disco.
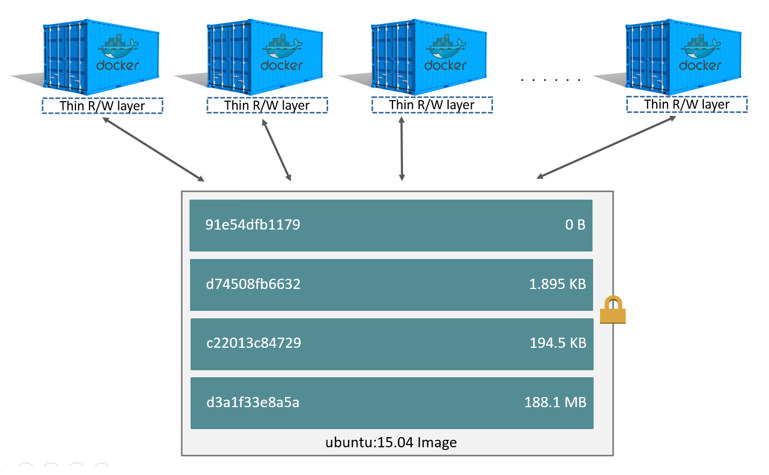
Fonte: Docker.com – Containers compartilhando layers
Na figura acima, a camada mais de baixo é uma imagem do Ubuntu na versão 15.04. Esta imagem contém os aplicativos e bibliotecas do Ubuntu na versão 15.04 e, no exemplo, possui 188.1 MB. Caso um Container fosse criado a partir dessa imagem, ele teria a seu dispor os mesmos aplicativos que uma máquina virtual com Ubuntu.
Logo acima da camada do Ubuntu, temos uma camada com 194.5 KB, depois uma camada com 1.895 KB, e por fim uma camada com 0B. Essas camadas intermediárias foram criadas sobre a camada do Ubuntu e podem ser novas aplicações que foram disponibilizadas, arquivos de configuração que foram personalizados, variáveis de ambiente definidas, etc. A camada com 0B é a camada de leitura/escrita, ou seja, é a camada que o container consegue escrever.
Todas as camadas abaixo da camada de leitura/escrita são apenas leitura, e é aí que vem a parte legal. Por não demandarem escrita, essas camadas podem ser reutilizadas entre vários containers, poupando espaço em disco. Ainda na Figura acima, não preciso possuir uma cópia da imagem ubuntu:15.04 para cada container: a mesma imagem serve para todos os containers.
Assim, além de não demandar um Kernel para cada container, o Docker possibilita a reutilização de imagens e camadas que são compartilhadas entre múltiplos containers, economizando muito espaço em disco. Está entendendo porque o negócio está fazendo tanto sucesso ?
Arquitetura do Docker
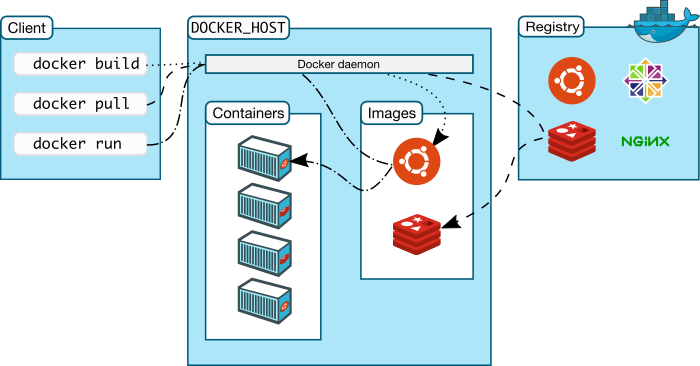
Fonte: Docker.com
– Arquitetura do Docker
Como você pode observar na figura acima, a arquitetura do Docker envolve:
- Docker Client: utilitário de linha de comando através do qual emitimos os comandos para construir as imagens dos containers (docker build), para baixar uma imagem (docker pull) ou para executar um container a partir de uma imagem (docker run);
- Docker Host: é a máquina que possui o Docker Daemon, ou Docker Server. É aqui onde os containers são efetivamente executados. O cliente envia os comandos para o Docker Server através de uma API REST (você não precisa conhecer os detalhes dessa API pois o Docker Cliente abstrai os detalhes) e o Docker Server é responsável por baixar as imagens e subir os containers a partir das imagens. No artigo Puppet: Subindo seus primeiros serviços e o Docker – DevOps Parte 5, provisionamos um Docker Server utilizando o Puppet e utilizamos o Docker Client para subir um container a partir da imagem hello-world com o comando:
- sudo docker run hello-world
- Docker Registry: é um repositório do Docker para manter as imagens criadas, permitindo reutilização. O maior repositório público de imagens é o Docker Hub, que já possui mais de 100 mil imagens disponíveis, sendo várias delas mantidas pelos próprios desenvolvedores das aplicações. Entre lá e faça algumas buscas por: httpd, ngnix, wordpress, pentaho, rails, wildfly, node. Você terá acesso imediato a imagens prontas com seus softwares favoritos já instalados. Basta subir o container e pronto (veremos exemplos em breve).
Se desejar, você também pode manter um Docker Registry próprio para hospedar suas imagens (caso não deseje publicá-las no Docker Hub). Para tanto, você pode usar a imagem registry, que é uma imagem com o servidor oficial de um repositório Docker, ou mesmo o Nexus 3, que já possui suporte para Registro Docker.
Conclusão
No próximo artigo da sequência de ferramentas de apoio a times DevOps, vamos subir um WordPress (com a base de dados) utilizando o Docker e imagens já prontas e disponibilizadas no DockerHub, tudo isso integrado ao ambiente que já montamos nas postagens anteriors:
- Puppet: Subindo seus primeiros serviços e o Docker – DevOps Parte 5
- Puppet: Instalação e fundamentos – DevOps Parte 4
- Gerenciamento de configuração e automação de servidores – DevOps Parte 3
- Vagrant: Crie sua própria box e disponibilize-a na Vagrant Cloud – DevOps Parte 2
- Vagrant: Turbine suas VMs e ambientes de desenvolvimento – DevOps Parte 1
Você vai ver com é simples e rápido subir um container no Docker. Fique ligado!
Espero que você tenha gostado! Agradeço se você puder curtir e compartilhar esse artigo em suas redes sociais.
Curta nossas páginas nas redes sociais para acompanhar novas postagens.
Em breve, mais conteúdos de qualidade para você aqui no Blog Eu na TI, o seu Blog sobre Tecnologia da Informação.
Um forte abraço e até mais.

Olá, sou Jonathan Maia, marido, pai, apaixonado por tecnologia, gestão e produtividade. Ocupo o cargo de Secretário de Tecnologia da Informação e Comunicação do Tribunal Regional do Trabalho do Ceará (TRT7) desde 2021, onde ingressei como servidor público federal (analista de TIC) no ano de 2010. Fui diretor da Divisão de Sistemas de TIC do TRT7 entre 2018 e 2020 e também tenho experiência prévia na Dataprev, Serpro e Ponto de Presença da Rede Nacional de Ensino e Pesquisa (RNP) no Ceará.
Graduado em ciências da computação pela Universidade Federal do Ceará e especialista em gerenciamento de projetos de TIC pela Universidade do Sul de Santa Catarina. Detentor das certificações em gestão e inovação: Project Management Professional © (PMP), Professional Scrum Master II © (PSM II), Professional Scrum Master I © (PSM I), Professional Scrum Product Owner I © (PSPO I), Kanban Management Professional © (KMP II), Certified Lean Inception Facilitator® (CLF), ISO 31000:2018 Risk Management Professional © e Project Thinking Essentials.
Desenvolvedor Full Stack, possuo experiência em diversas arquiteturas / plataformas de desenvolvimento. Já tive experiências profissionais em redes metropolitanas de alta velocidade (GigaFOR/RNP), business intelligence, desenvolvimento de sistemas, gestão de projetos e produtos, governança, etc. Experiência em dezenas de projetos com abordagens de gestão ágeis, híbridas e tradicionais, incluindo projeto com menção honrosa no Prêmio de Excelência em Governo Eletrônico (e-Gov).
Com dezenas de turmas de capacitação, oficinas ou palestras ministradas nas temáticas de gestão ágil, gestão de projetos, tecnologia, inovação e produtividade nas seguintes instituições: Conselho Superior da Justiça do Trabalho (CSJT), Tribunal de Justiça do Distrito Federal e Territórios (TJDFT), Tribunais Regionais do Trabalho do Ceará (TRT7), Pará e Amapá (TRT8), Sergipe (TRT20), Rio Grande do Norte (TRT21), Tribunais Regionais Eleitorais do Ceará (TRE-CE), Mato Grosso do Sul (TRE-MS) e da Bahia (TRE-BA), Justiça Federal em Sergipe (JF-SE), Justiça Federal no Ceará (JF-CE), Companhia Siderúrgica do Pecém (CSP), Instituto Federal do Ceará (IF-CE), Instituto Federal do Rio Grande do Norte (IF-RN), Banco do Nordeste do Brasil (BNB), Gagliardi (Mobil), Udemy, Companhia Cearense de Gás (CEGÁS), Agile Trends Gov, Project Management Institute (PMI-CE), Cagece, Faculdade Estácio e Associação de Gerenciamento de Projetos do Mato Grosso do Sul (AGPMS).
Comments
Pingback: Puppet: Subindo seus primeiros serviços e o Docker - DevOps Parte 5 - Eu na TI
Pingback: #18 Docker com Giovanni Bassi – Cafe debug
Pingback: Puppet: Instalação e fundamentos - DevOps Parte 4 - Eu na TI - Por Jonathan Maia